
1. Ma trận xoay nhân tố bị xáo trộn, lộn xộn và không hội tụ là gì?
Trong phân tích EFA, ma trận xoay nhân tố là kết quả sau khi thực hiện phép xoay (rotation) nhằm mục đích làm rõ cấu trúc của các nhân tố. Một ma trận xoay nhân tố lý tưởng sẽ cho thấy các biến quan sát (observed variables) được nhóm lại thành các nhân tố (factors) một cách rõ ràng, mỗi biến quan sát sẽ có tải số (factor loading) cao ở một nhân tố duy nhất và thấp ở các nhân tố còn lại.
Tuy nhiên, trong thực tế, đôi khi ma trận xoay nhân tố thu được lại bị xáo trộn, lộn xộn, các biến quan sát không được nhóm rõ ràng vào các nhân tố, hoặc có nhiều biến quan sát có tải số cao ở nhiều nhân tố. Đây là hiện tượng ma trận xoay nhân tố bị xáo trộn, lộn xộn và không hội tụ.
2. Ma trận xoay EFA lộn xộn có phải là xấu?
Phân tích nhân tố khám phá EFA là một bước quan trọng giúp chúng ta xác định các nhân tố tiềm ẩn và so sánh chúng với cơ sở lý luận ban đầu. Việc xuất hiện nhân tố mới, điều chỉnh số lượng nhân tố hoặc thay đổi cấu trúc thang đo là điều hoàn toàn bình thường. Do đó, nếu trong quá trình phân tích, một số biến chuyển từ nhóm này sang nhóm khác, hai nhóm gộp lại thành một, hoặc một nhóm bị loại bỏ hoàn toàn sau nhiều lần chạy EFA, thì đó không hẳn là dấu hiệu tiêu cực đối với dữ liệu khảo sát.
Tuy nhiên, việc phát hiện ra nhân tố mới có thể tạo ra giá trị mới cho nghiên cứu, nhưng nếu ma trận xoay trở nên hỗn loạn, phần lớn các biến bị xáo trộn khỏi nhóm ban đầu, số nhân tố mới hình thành quá nhiều, hoặc một thang đo mới chỉ còn 2-3 biến được gộp từ nhiều nhóm khác nhau, thì đó thực sự là một vấn đề đáng lưu ý.
3. Nguyên nhân gây ra ma trận xoay nhân tố bị xáo trộn, lộn xộn và không hội tụ
Có nhiều nguyên nhân dẫn đến hiện tượng ma trận xoay nhân tố bị xáo trộn, lộn xộn và không hội tụ, bao gồm:
- Dữ liệu không đạt chất lượng: Dữ liệu thu thập được có thể bị thiếu, sai lệch, hoặc không tuân theo phân phối chuẩn.
- Mẫu quá nhỏ: Kích thước mẫu không đủ lớn để đảm bảo độ tin cậy của kết quả phân tích nhân tố.
- Số lượng biến quan sát và nhân tố không phù hợp: Số lượng biến quan sát quá ít so với số lượng nhân tố, hoặc ngược lại, có thể dẫn đến kết quả không rõ ràng.
- Phương pháp xoay không phù hợp: Có nhiều phương pháp xoay khác nhau (ví dụ: Varimax, Promax), việc lựa chọn phương pháp không phù hợp có thể ảnh hưởng đến kết quả.
- Mô hình nhân tố không phù hợp: Mô hình nhân tố được thiết lập ban đầu có thể không phù hợp với dữ liệu.
4. Cách xử lý ma trận xoay lộn xộn, không hội tụ
4.1 Chạy EFA riêng theo vai trò biến
Việc xác định vai trò của các biến trong mô hình trước khi triển khai EFA là rất quan trọng. Trong nhiều trường hợp, cùng một bộ dữ liệu nhưng khi phân tích EFA riêng lẻ thì kết quả tốt, còn khi chạy EFA chung lại cho kết quả kém, thậm chí có thể phải loại bỏ toàn bộ dữ liệu.
Một ví dụ điển hình là mối quan hệ giữa biến độc lập và biến phụ thuộc trong mô hình. Khi biến độc lập có khả năng giải thích tốt cho biến phụ thuộc, nếu đưa cả hai loại biến này vào cùng một lần phân tích EFA, rất có thể nhân tố của biến phụ thuộc sẽ không tách biệt rõ ràng với nhân tố của biến độc lập trong ma trận xoay. Do đó, việc kết luận rằng ma trận xoay xấu và dữ liệu không thể sử dụng được chỉ vì nhân tố của biến độc lập không tách riêng khỏi biến phụ thuộc là thiếu cơ sở và không hợp lý.
Mình đã phân tích chi tiết về cách chạy EFA chung/riêng trên SPSS cũng như một số quan điểm nghiên cứu liên quan trong bài viết Phân tích EFA chung hay riêng biến độc lập và biến phụ thuộc. Các bạn có thể truy cập link để xem thêm thông tin.
4.2 Xác định dạng ma trận xoay lộn xộn có thể cải thiện được
Ma trận xoay trong EFA là kết quả phản ánh từ dữ liệu đầu vào. Kỹ thuật xử lý không làm thay đổi bản chất dữ liệu đầu vào kém chất lượng thành một dữ liệu tốt mà chỉ cải thiện dữ liệu hoặc kết quả EFA để thu về một ma trận xoay phù hợp nhất với tập dữ liệu.
Nếu chất lượng dữ liệu đầu vào quá tệ và rơi vào những tình huống không thể xử lý, cải thiện được. Bạn không nên mất thời gian để xử lý khắc phục ma trận xoay EFA nữa mà nên dành thời gian đó để điều chỉnh lại bảng câu hỏi, tiến hành khảo sát lại một cách kỹ lưỡng để có được một bộ dữ liệu mới phù hợp.
Vậy thì đâu sẽ là biểu hiện của một ma trận xoay xáo trộn có thể xử lý được và không xử lý được?
Dạng ma trận xoay lộn xộn có thể cải thiện:
– Số cấu trúc nhân tố mới giảm đi hoặc tăng lên rất ít so với số nhân tố lý thuyết;
– Số nhân tố giữ được cấu trúc biến quan sát theo lý thuyết nhiều hơn số nhân tố bị vỡ cấu trúc lý thuyết;
– Cấu trúc nhân tố lý thuyết bị phá vỡ nhẹ.
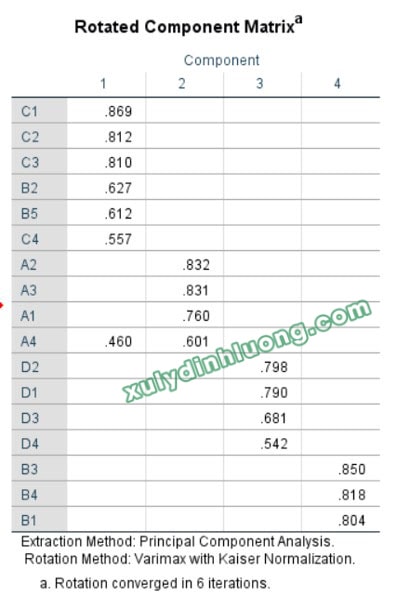
Dạng ma trận xoay lộn xộn có thể cải thiện
Dạng ma trận xoay lộn xộn không thể cải thiện:
– Trích ra quá nhiều nhân tố so với số nhân tố lý thuyết;
– Gộp lại chỉ còn 1, 2 nhân tố từ số nhiều nhân tố lý thuyết;
– Cấu trúc các nhân tố bị phá vỡ hoàn toàn;
– Quá nhiều nhân tố là hỗn hợp biến quan sát từ nhiều nhân tố.
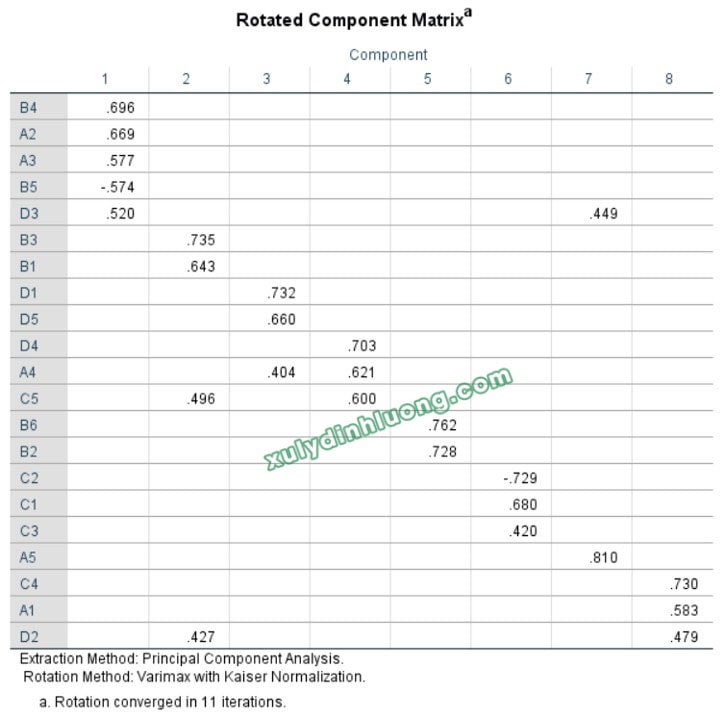
Dạng ma trận xoay lộn xộn không thể cải thiện
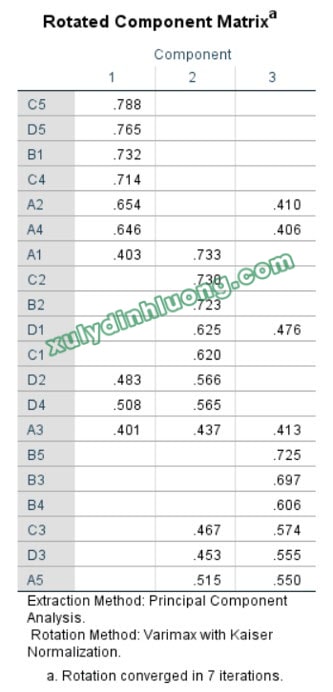
Dạng ma trận xoay lộn xộn không thể cải thiện
→ Với dạng không thể cải thiện được này, dữ liệu đầu vào không đạt chất lượng, chúng ta cần tiến hành điều chỉnh bảng hỏi, thu thập lại dữ liệu mới.
Tham khảo: Tổng hợp 20 bộ dữ liệu SPSS mẫu kết quả tốt
4.3 Xử lý ma trận xoay xáo trộn, không hội tụ
Khi đã xác định ma trận xoay thuộc vào dạng có thể xử lý, cải thiện được. Chúng ta sẽ đánh giá tổng quan sự xáo trộn của ma trận xoay để đưa ra hướng xử lý.
Bước 1: Hãy đảm bảo rằng trong bước kiểm định độ tin cậy thang đo bằng Cronbach’s Alpha, chúng ta đã loại bỏ các biến quan sát và nhân tố không phù hợp. Những biến và nhân tố đã bị loại bỏ ở bước này sẽ không được đưa vào phân tích EFA.
Bước 2: Thực hiện thống kê trung bình để kiểm tra xem có biến nào có giá trị nằm ngoài phạm vi thang đo hoặc có dấu hiệu bất thường về giá trị trung bình (mean), giá trị nhỏ nhất (min), giá trị lớn nhất (max) và độ lệch chuẩn (standard deviation). Ví dụ, nếu giá trị max là 55 trong khi thang đo chỉ từ 1-5, thì có thể đã xảy ra lỗi nhập dữ liệu. Hoặc nếu độ lệch chuẩn lên đến 2 trong khi thang đo chỉ từ 1-5, điều này cho thấy đáp án quá chênh lệch, có khả năng biến này gặp vấn đề. Bạn có thể xem hướng dẫn chi tiết về cách chạy thống kê trung bình tại đây.
Bước 3: Tiếp tục kiểm tra và loại bỏ các phiếu khảo sát có dấu hiệu trả lời không nghiêm túc, chẳng hạn như chọn cùng một đáp án cho tất cả các câu hỏi. Ví dụ, nếu một đáp viên chọn toàn bộ đáp án là 5 từ đầu đến cuối, đây là dấu hiệu của phiếu khảo sát kém chất lượng và cần được loại bỏ. Nếu có quá nhiều phiếu như vậy, dữ liệu có thể gặp phải vấn đề CMB (Common Method Bias), đa cộng tuyến, và vi phạm tính phân biệt, dẫn đến ma trận xoay không thể tách biệt rõ các yếu tố.
Bước 4: Kiểm tra tính logic của dữ liệu trong các câu hỏi về thông tin cá nhân để phát hiện và loại bỏ các phiếu khảo sát không hợp tác. Ví dụ, nếu một đáp viên khai báo độ tuổi dưới 18 nhưng trình độ học vấn là sau đại học, điều này cho thấy phiếu khảo sát kém chất lượng, có khả năng đáp viên trả lời một cách tùy tiện mà không đọc và hiểu câu hỏi.
Bước 5: Tiến hành nhận diện các biến quan sát xấu và loại bỏ chúng ra khỏi kết quả EFA. Chi tiết về phần xác định và loại bỏ biến xấu bạn xem tại đây.
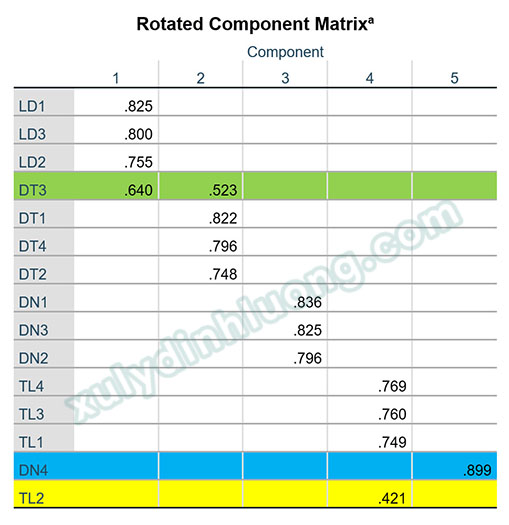
Như ví dụ ở trên, các biến quan sát xấu cần loại bỏ gồm:
- Biến DT3: biến này tải mạnh lên cả hai nhân tố DT và LD, đây là một biến không rõ ràng vì giải thích cùng lúc cho cả hai yếu tố, cần loại bỏ đi.
- Biến DN4: biến này theo lý thuyết thuộc về nhân tố DN nhưng khi phân tích EFA lại nằm tách riêng thành một nhân tố. Một biến quan sát tách làm một nhân tố sẽ không phù hợp về mặt đại diện cho ý nghĩa nhân tố, chúng ta sẽ loại đi biến quan sát này.
- Biến TL2: biến này vẫn hội tụ tốt về nhân tố TL. Tuy nhiên, nghiên cứu này tác giả chỉ chọn lọc các biến quan sát có hệ số tải tối thiểu từ 0.5 trở lên để đảm bảo chất lượng của đề tài. Biến quan sát TL2 có hệ số tải bằng 0.421 < 0.5, cho thấy biến này giải thích cho nhân tố TL khá yếu, do vậy sẽ cần loại bỏ đi.
Quá trình loại bỏ các biến quan sát không phù hợp có thể được thực hiện theo hai cách: loại bỏ đồng loạt hoặc loại từng biến rồi chạy lại phân tích. Chúng ta sẽ linh hoạt kết hợp cả hai phương pháp này để đảm bảo ma trận xoay tạo ra cấu trúc nhân tố phù hợp nhất với lý thuyết ban đầu.
Bước 6: Sau khi loại bỏ các biến quan sát không phù hợp, những nhân tố vẫn giữ nguyên cấu trúc lý thuyết (tức là chỉ bao gồm các biến quan sát gốc mà không bị xáo trộn với biến từ nhân tố khác) sẽ được giữ nguyên tên theo lý thuyết ban đầu mà không cần điều chỉnh thêm.
Đối với những nhân tố mới hình thành có sự xáo trộn biến quan sát, chúng ta cần kiểm tra lại ý nghĩa nội dung của các biến bị xáo trộn để đánh giá mức độ hợp lý. Nếu sự hội tụ này có cơ sở, các biến quan sát cùng thể hiện một nội dung chung, thì sẽ tiến hành đặt tên cho nhân tố mới theo hướng dẫn trong bài viết này để xác định các thang đo mới.
4.4 Kết luận chung về việc khắc phục ma trận xoay EFA xáo trộn
Dưới đây sẽ là một số nhận định, kết luận khi xử lý vấn đề ma trận xoay lộn xộn, không hội tụ:
-
Ma trận xoay xáo trộn không đồng nghĩa với kết quả nghiên cứu kém chất lượng. Trước khi kết luận tiêu cực, hãy xem xét tính hợp lý của sự xáo trộn này, vì đôi khi đây có thể là một phát hiện mới có giá trị trong nghiên cứu.
-
Sự khác biệt về bối cảnh có thể ảnh hưởng đến kết quả EFA. Dù bảng câu hỏi hay thang đo được kế thừa từ những nghiên cứu trước, khi áp dụng vào một môi trường khác (quốc gia, thời điểm, đặc điểm đối tượng khảo sát…), các yếu tố này có thể gây ra sai lệch trong kết quả phân tích. Do đó, không nhất thiết ma trận xoay EFA trong nghiên cứu thực nghiệm phải hoàn toàn khớp với cấu trúc lý thuyết mới được xem là đúng.
-
Chất lượng dữ liệu đầu vào quyết định độ ổn định của ma trận xoay. EFA và các kiểm định khác phản ánh chất lượng của dữ liệu thu thập. Vì vậy, cần đảm bảo bảng câu hỏi được thiết kế rõ ràng, bố cục hợp lý, câu hỏi dễ hiểu và đáp viên được chọn lọc kỹ lưỡng. Nếu thực hiện tốt các bước tiền khảo sát, quá trình phân tích định lượng sau đó sẽ ít gặp vấn đề hơn.
Nếu bạn gặp khó khăn khi kết quả EFA bị xáo trộn, không đạt tiêu chuẩn kiểm định, số biến bị loại quá nhiều. Bạn có thể tham khảo dịch vụ SPSS của Xử Lý Định Lượng để team có thể hỗ trợ bạn xử lý nhanh và hiệu quả nhất.










