Ở bài viết Đánh giá mô hình đo lường dạng kết quả trên SMARTPLS, chúng ta đã nắm được những kết quả nào cần sử dụng trong một mô hình đo lường dạng kết quả reflective. Phạm vi bài viết này, chúng ta sẽ tiếp tục xét đến dạng mô hình nguyên nhân formative. Bạn có thể xem lý thuyết về mô hình kết quả, nguyên nhân tại bài viết Mô hình nguyên nhân (formative) và kết quả (reflective) trong PLS-SEM.
1. Khác biệt về đánh giá mô hình đo lường dạng nguyên nhân và kết quả
Sự khác biệt hoàn toàn về mối quan hệ giữa biến tiềm ẩn và biến quan sát giữa mô hình nguyên nhân và mô hình kết quả dẫn đến việc đánh giá mô hình đo lường giữa hai dạng này cũng có sự khác biệt đáng kể. Chúng ta không sử dụng các tiêu chí đánh giá mô hình đo lường kết quả để đánh giá chất lượng của mô hình đo lường nguyên nhân bởi trong mô hình nguyên nhân, các biến quan sát được kỳ vọng là không có sự tương quan cao.
Việc đánh giá giá trị hội tụ (convergent validity), tính phân biệt (discriminant validity) của mô hình đo lường nguyên nhân khi sử dụng các tiêu chí tương tự với mô hình đo lường kết quả là không có ý nghĩa (A Primer on Partial Least Squares Structural Equation Modeling, Hair và cộng sự, 2021).
Đặc trưng của thang đo dạng nguyên nhân đó là nhà nghiên cứu phải xây dựng được đầy đủ biến quan sát chứa đựng được tất cả (hoặc ít nhất là điểm chính) các mặt của biến tiềm ẩn. Chúng ta phải liệt kê một tập hợp toàn diện các biến quan sát thể hiện tất cả những gì liên quan đến phạm vi của biến tiềm ẩn nguyên nhân. Việc xác định thiếu các biến quan sát quan trọng sẽ khiến cho biến tiềm ẩn mẹ không thể hiện được đúng tính chất của nó.
Khi đánh giá mô hình đo lường dạng nguyên nhân trên SMARTPLS, chúng ta sẽ tập trung vào các vấn đề chính: tính hội tụ của thang đo, vấn đề cộng tuyến của biến quan sát, chất lượng biến quan sát (chỉ báo). Để đánh giá các tiêu chí này, chúng ta cần chạy hai phân tích PLS Algorithm và Bootstrapping cho mô hình.
2. Tính hội tụ thang đo nguyên nhân
Bởi vì giả định của thang đo nguyên nhân là các biến quan sát không có sự tương quan với nhau, chúng ta không thể đánh giá tính hội tụ thang đo như dạng thang đo kết quả thông qua các chỉ số như Cronbach’s Alpha, CR, AVE. Một kỹ thuật các nhà nghiên cứu hiện đang sử dụng để đánh giá tính hội tụ thang đo nguyên nhân đó là phân tích phần dư (redundancy analysis).
Cách hoạt động của kỹ thuật này như sau. Một biến tiềm ẩn có thể được đo lường theo cả hai dạng thang đo nguyên nhân và thang đo kết quả. Gọi biến tiềm ẩn khi đo bằng thang đo nguyên nhân là Y_f, gọi biến tiềm ẩn khi đo bằng thang đo kết quả là Y_r. Thực hiện phân tích đường dẫn với biến độc lập là Y_f và biến phụ thuộc là Y_r. Độ mạnh của hệ số tác động từ Y_f lên Y_r là thước đo tính hội tụ của Y_f. Theo Hair và cộng sự (A Primer on Partial Least Squares Structural Equation Modeling, 2021), độ lớn hệ số tác động (Original Sample) từ 0.7 trở lên là phù hợp. Hệ số tác động từ Y_f lên Y_r tối thiểu bằng 0.7 sẽ tương ứng giá trị R2 tối thiểu của mối tác động này là 0.5 (50%). Điều này nói lên rằng, nếu kết quả phân tích cho thấy hệ số tác động từ Y_f lên Y_r dưới 0.7 hoặc R2 mối tác động này dưới 50% thì tính hội tụ của thang đo nguyên nhân bị vi phạm, thang đo không đảm bảo tính hội tụ cần thiết cho phân tích. Khi thang đo nguyên nhân vi phạm tính hội tụ, chúng ta cần phải xem xét lại các lý thuyết để đổi biến quan sát hoặc bổ sung thêm biến quan sát cho đến khi thang đo đảm bảo dược tính hội tụ.
Về bản chất của kỹ thuật sẽ là vậy nhưng trên thực tế, thường do là chúng ta không thể xây dựng được thang đo kết quả, chúng mới chuyển hướng sang xây dựng theo dạng nguyên nhân. Nhưng kỹ thuật phân tích phần dư (redundancy analysis) lại yêu cầu phải có thang đo kết quả thì mới đánh giá được thang đo nguyên nhân. Thành ra vấn đề lại quay về trạng thái ban đầu, không có hướng giải quyết phù hợp.
Hiểu được điều này, các nhà nghiên cứu đã sử dụng đến biến tổng quát (global variable). Thay vì phải xây dựng một thang đo kết quả là điều quá khó khăn, nhà nghiên cứu chỉ cần sử dụng một biến kết quả tổng quát. Lúc này, Y_r chỉ có một biến quan sát duy nhất, đây chính là biến tổng quát.
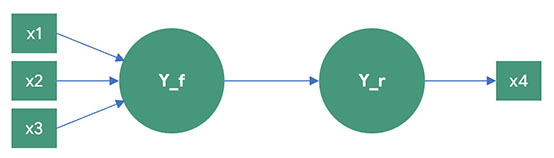
Ví dụ, biến tiềm ẩn Y_f (Sự hài lòng dịch vụ xe ôm) được xây dựng dạng nguyên nhân qua ba biến quan sát x1 (Tài xế khá thân thiện), x2 (Quy trình booking xe dễ thực hiện), x3 (Dịch vụ chăm sóc khách hàng hỗ trợ tốt) được đánh giá theo thước đo Likert 5 mức độ đồng ý. Để đánh giá được độ tin cậy của Y_f, chúng ta xây dựng nên Y_r gồm một biến quan sát tổng quát x4 (Nhìn chung, anh/chị hài lòng với dịch vụ xe ôm Grab). Với biến tổng quát, chúng nên sử dụng thước đo có nhiều mức độ hơn để kết quả chính xác hơn, cụ thể trong trường hợp này sẽ dùng 7 đến 10 mức độ đồng ý (1: hoàn toàn không đồng ý và 10: hoàn toàn đồng ý).
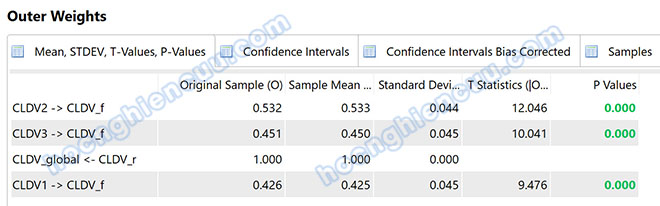
Ví dụ: Nhà nghiên cứu muốn đánh giá tính hội tụ thang đo nguyên nhân CLDV gồm ba biến quan sát CLDV1, CLDV2, CLDV3. Kết quả phân tích trên SMARTPLS từ PLS Algorithm cho thấy hệ số đường dẫn (Original Sample) từ biến tiềm ẩn nguyên nhân lên biến tiềm ẩn kết quả (đo theo biến quan sát tổng quát) là 0.871 > 0.7. Như vậy, thang đo CLDV đảm bảo tính hội tụ.
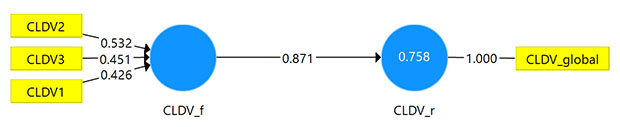
3. Vấn đề cộng tuyến biến quan sát trong thang đo nguyên nhân
Trong mô hình nguyên nhân, các biến quan sát luôn được kỳ vọng không có sự tương quan quá mạnh. Việc cộng tuyến/đa cộng tuyến nghiêm trọng giữa các biến quan sát sẽ ảnh hưởng đến việc ước lượng các trọng số trong mô hình (biến tác động mạnh thành tác động yếu, biến tác động dương thành tác động âm…) và mức ý nghĩa thống kê các kiểm định liên quan (kiểm định có ý nghĩa thống kê nhưng lại thành không có ý nghĩa thống kê và ngược lại).
Để đánh giá vấn đề cộng tuyến trong mô hình nguyên nhân, chúng ta sẽ dựa vào Outer VIF Values từ kết quả phân tích PLS Algorithm trên SMARTPLS. Hair và cộng sự (2011) cho rằng nếu VIF từ mức 5 trở lên là dấu hiệu của việc tồn tại vấn đề cộng tuyến trong mô hình. Để xử lý đa cộng tuyến, chúng ta sẽ loại biến có VIF cao nhất, sau đó đánh giá lại kết quả của mô hình. Quá trình này được thực hiện lặp lại đến khi không còn tình trạng cộng tuyến. Tuy nhiên, nhà nghiên cứu cũng cần phải đảm bảo số lượng biến còn lại vẫn thể hiện được đầy đủ nội dung của biến tiềm ẩn mẹ từ quan điểm lý thuyết.
Ví dụ: Cũng từ ví dụ biến nguyên nhân CLDV ở mục số 2, kết quả phân tích tính cộng tuyến từ PLS Algorithm giữa các biến quan sát cho thấy Outer VIF Values CLDV1, CLDV2, CLDV3 đều rất nhỏ (dưới ngưỡng 5). Như vậy, không xảy ra tình trạng cộng tuyến giữa các biến quan sát nguyên nhân của thang đo CLDV.

4. Chất lượng biến quan sát trong thang đo nguyên nhân
Một tiêu chí quan trọng khác để đánh giá sự đóng góp của một biến quan sát nguyên nhân và mức độ liên quan của nó, gọi là trọng số ngoài của nó (outer weights).
Trọng số ngoài là kết quả của hồi quy bội với biến tiềm ẩn mẹ đóng vai trò là biến phụ thuộc và các biến quan sát nguyên nhân như các biến độc lập. Giá trị của các trọng số ngoài được chuẩn hóa và có thể được so sánh với nhau, biến quan sát có trọng số ngoài lớn hơn nghĩa là nó đóng góp vào biến mẹ tốt hơn.
Không có ngưỡng giá trị trọng số ngoài (outer weights) bao nhiêu là tốt/không tốt như là hệ số tải ngoài (outer loadings). Để trả lời cho câu hỏi biến quan sát nguyên nhân có thực sự đóng góp vào việc hình thành biến tiềm ẩn mẹ hay không, chúng ta phải kiểm định chúng thông qua kỹ thuật bootstrapping. Nếu sử dụng mức ý nghĩa 5%, giá trị p-value kiểm định t sự tác động của biến quan sát nguyên nhân nhỏ hơn 0.05 cho thấy biến quan sát đó có ý nghĩa, nếu p-value lớn hơn 0.05, biến quan sát đó không có ý nghĩa.
Theo Hair và cộng sự (2011), khi trọng số ngoài của biến quan sát nguyên nhân không có ý nghĩa nhưng hệ số tải ngoài trên 0.5, biến quan sát sẽ được giữ lại. Nếu biến quan sát không có ý nghĩa và hệ số tải ngoài cũng nhỏ hơn 0.5, biến quan sát nên được loại bỏ.
Ví dụ: Cũng từ ví dụ biến nguyên nhân CLDV ở mục số 2, kết quả phân tích Bootstrapping cho giá trị p-value các biến quan sát CLDV1, CLDV2, CLDV3 đều bằng 0.000 < 0.05. Như vậy, các biến quan sát đều có đóng góp vào biến tiềm ẩn mẹ một cách có ý nghĩa thống kê.