
Phân tích cấu trúc đa nhóm (multigroup analysis) giúp đánh giá sự khác biệt các mối tác động trong mô hình SEM giữa các giá trị khác nhau của biến định tính hay nói cách khác là xem mô hình có khác nhau giữa các đối tượng khác nhau hay không. Đây là ứng dụng phổ biến nhất của phân tích cấu trúc đa nhóm trong thực hiện luận văn hiện nay.
1. Chức năng của phân tích đa nhóm Multigroup Analysis
Chúng ta có một mô hình SEM biểu diễn mối tác động từ Chất lượng dịch vụ (CLDV) lên Sự hài lòng của khách hàng (SHL). Trong dữ liệu phân tích SEM này có câu hỏi định tính là giới tính gồm 2 giá trị nam và nữ. Chúng ta muốn đánh giá xem nam/nữ có ảnh hưởng lên mối quan hệ từ CLDV lên SHL hay không? Nếu có ảnh hưởng thì sự ảnh hưởng đó thế nào? Ví dụ:
- Với đáp viên nam thì CLDV không có tác động lên SHL nhưng với nữ thì lại có;
- Hoặc ở cả nam và nữ thì CLDV đều tác động lên SHL, nhưng với đáp viên nam thì CLDV tác động lên SHL mạnh hơn so với nữ (hệ số tác động chuẩn hóa của nam cao hơn của nữ)…
Các chỉ số thường dùng để đánh giá sự khác biệt mối tác động trong phân tích đa nhóm multigroup thường là:
- Giá trị sig hoặc p-value (AMOS ký hiệu là p-value) dùng để xem mối tác động đó có ý nghĩa hay không ở từng nhóm đối tượng.
- Giá trị standardized regression weights (hệ số hồi quy chuẩn hóa) dùng để xem sự tác động ở đối tượng này thấp hay cao hơn nhóm đối tượng khác.
- Giá trị squared multiple correlation (R bình phương) dùng để xem mức độ giải thích của biến độc lập lên biến phụ thuộc trong một mối quan hệ tác động giữa các nhóm đối tượng khác nhau thì cao thấp ra sao.
Tránh nhầm lẫn chức năng của “Phân tích đa nhóm Multigroup” với “Phân tích phương sai One-way ANOVA“:
- Multigroup Analysis: đánh giá sự khác biệt CÁC MỐI QUAN HỆ TÁC ĐỘNG trong mô hình giữa các giá trị khác nhau của biến định tính. Ví dụ: xem CLDV tác động lên HL khác nhau như thế nào giữa nam và nữ.
- One-way ANOVA: đánh giá sự khác biệt MỘT BIẾN ĐỊNH LƯỢNG giữa các giá trị khác nhau của biến định tính. Ví dụ: xem HL khác nhau như thế nào giữa nam và nữ.
2. Cơ chế của phân tích đa nhóm Multigroup Analysis
Theo cách tiếp cận truyền thống của Joreskog (1971), để đánh giá có sự khác biệt một mô hình giữa các đối tượng khác nhau hay không, chúng ta sẽ dựa vào sự chênh lệch của giá trị Chi-square (Chi bình phương) trong mối ràng buộc với bậc tự do (df) giữa mô hình khả biến và mô hình bất biến.
Mô hình khả biến là mô hình các hệ số tác động của đường dẫn được để tự do. Trong khi đó với mô hình bất biến, chúng ta sẽ có định hệ số tác động tất cả các đường dẫn của mô hình cấu trúc SEM. Để hệ số tác động tự do hoặc cố định là như thế nào chúng ta sẽ làm rõ trong ví dụ thực hành.
Sau khi phân tích SEM cho hai mô hình khả biến và bất biến, thu được giá trị Chi-square và bậc tự tự do df ở từng mô hình. Thực hiện kiểm định sự khác biệt Chi-square theo bậc tự do giữa hai mô hình này, giả thiết đặt ra:
- H0: Không có sự khác biệt giữa hai mô hình bất biến và khả biến
- H1: Có sự khác biệt giữa hai mô hình bất biến và khả biến
Nếu H0 không bị bác bỏ, chúng ta sẽ chọn mô hình bất biến để giải thích kết quả do mô hình có bậc tự do cao hơn. Nếu H0 bị bác bỏ, có nghĩa giữa hai mô hình có sự khác biệt đáng kể, chúng ta sẽ chọn mô hình khả biến để giải thích kết quả.
Dựa trên cơ chế này chúng ta sẽ biết trước sẽ cần chuẩn bị các thông tin sau:
- Mỗi lần phân tích cấu trúc đa nhóm chỉ thực hiện cho một biến định tính. Nếu có nhiều biến định tính chúng ta sẽ thực hiện lần lượt.
- Muốn phân tích cấu trúc đa nhóm cho một biến định tính, chúng ta cần 2 diagram SEM cho biến định tính đó. Một cái là diagram biểu diễn mô hình bất biến (MHBB), một cái là diagram biểu diễn mô hình khả biến (MHKB). Như vậy, giả sử có hai biến định tính, thì chúng ta cần bốn diagram.
- Khi phân tích cấu trúc đa nhóm cho một biến định tính, chung ta cần lấy được 2 giá trị quan trọng ở từng MHBB, MHKB là Chi-square và df.
- Cần thực hiện kiểm định khác biệt Chi-square theo bậc tự do để có được giá trị p-value phục vụ cho việc kết luận giả thiết đặt ra từ đầu.
3. Phân tích đa nhóm Multigroup Analysis trên AMOS
Dưới đây là một mô hình nghiên cứu ví dụ. Đi với mô hình này là một tập data đã được thu thập với cỡ mẫu 345. Trước khi đi vào phần hướng dẫn, mình xin trả lời các câu hỏi có thể xảy ra khi xem bài viết này:
- Cho mình xin file dữ liệu thực hành của bài viết được không?
→ Vì nhiều lý do, mình không thể share dữ liệu bạn nhé. - Có quá nhiều chỗ trong bài viết này mình không hiểu, có thể giải thích chi tiết hơn cho mình qua zalo hoặc điện thoại được không?
→ Phần phân tích cấu trúc đa nhóm này nếu các bạn chưa được học thì sẽ hơi khó một chút lúc mới làm quen. Trong bài viết mình đã cố gắng hết sức có thể để diễn giải từng bước một cách dễ hiểu nhất. Nếu các bạn thấy không hiểu hãy cố gắng đọc chậm, đọc thật kỹ, chuẩn bị trước kiến thức về đọc hiểu kết quả SEM tại bài viết này. Bắt buộc phải chạy được phân tích SEM, phải đọc được kết quả phân tích SEM thì mới xem bài này. Mình sẽ không hỗ trợ bằng bất kỳ hình thức nào với các thao tác thực hiện kiểm định + đọc kết quả. Mình có thể hỗ trợ về mặt phát sinh lỗi khi thực hiện kiểm định.
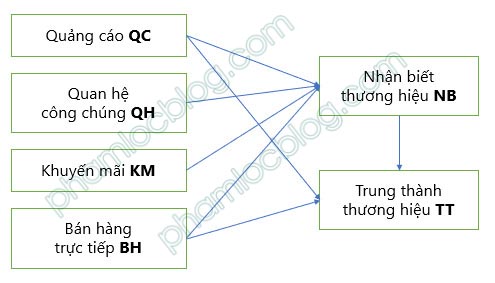
Mỗi biến tiềm ẩn được đo lường qua các biến quan sát, tất cả chúng được biểu diễn thông qua diagram mô hình SEM trên AMOS như sau.
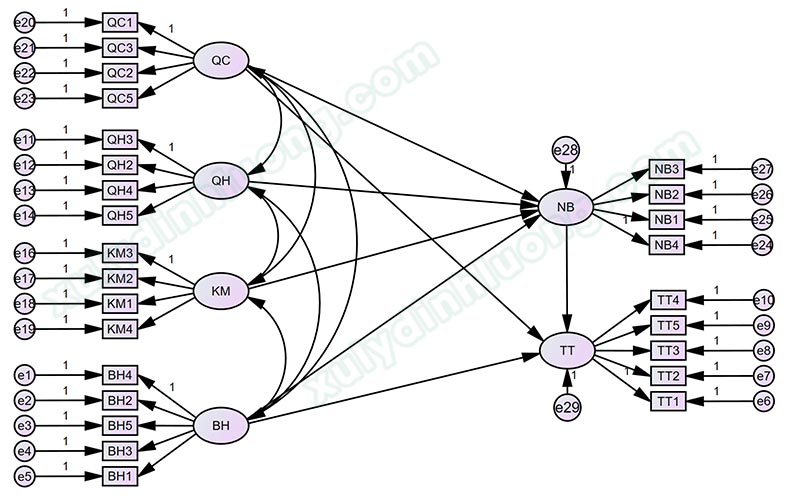
Data mẫu này có hai biến định tính là giới tính và độ tuổi được chia làm các nhóm giá trị:
- Giới tính: Nam; Nữ
- Độ tuổi: Dưới 18 tuổi; Từ 18 – 35 tuổi; Từ 36 – 50 tuổi; Trên 50 tuổi
Chúng ta thực hiện phân tích cấu trúc đa nhóm để xem xét sự khác biệt mô hình SEM với các giá trị khác nhau của ở từng biến định tính.
3.1 Phân tích cấu trúc đa nhóm cho biến Giới tính
Lưu ý rằng, Multigroup Analysis sẽ được thực hiện sau bước phân tích SEM. Do đó nếu chưa thực hiện SEM, các bạn cần hoàn thiện phân tích này trước.
Bước 1: Như đã đề cập ở phần thông tin chuẩn bị, chúng ta cần 2 file diagram tương ứng với MHBB và MHKB cho biến Giới tính. Chúng ta sẽ tạo lần lượt từng file. Lưu diagram SEM thành một file mới với tên GT-BB.
Bước 2: Chèn macro lấy giá trị Chi-square và df ra ngoài diagram. Nếu trước đó phân tích SEM các bạn đã có 2 macro này ồi thì không cần thay đổi. Cấu trúc macro như sau:
Chi-square=\cmin
df=\df
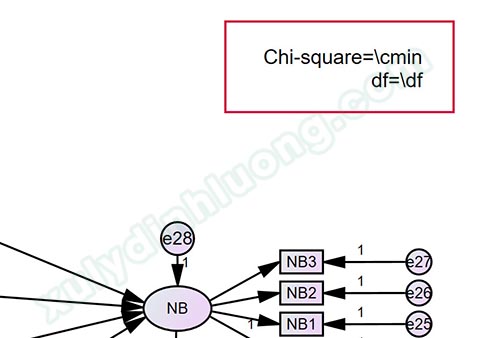
Bước 3: Cố định hệ số tác động vào các đường dẫn mô hình cấu trúc bằng cách nhấp đôi chuột vào đường dẫn > Chuyển sang thẻ Parameters > Điền hệ số tác động vào ô Regression weight.
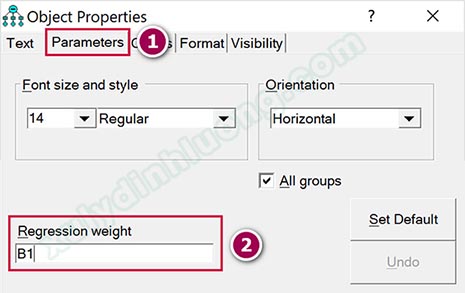
Có thể dùng ký hiệu là B1, B2, B3… để điền vào toàn bộ các đường dẫn mô hình cấu trúc. Kết quả cuối cùng có được như sau.
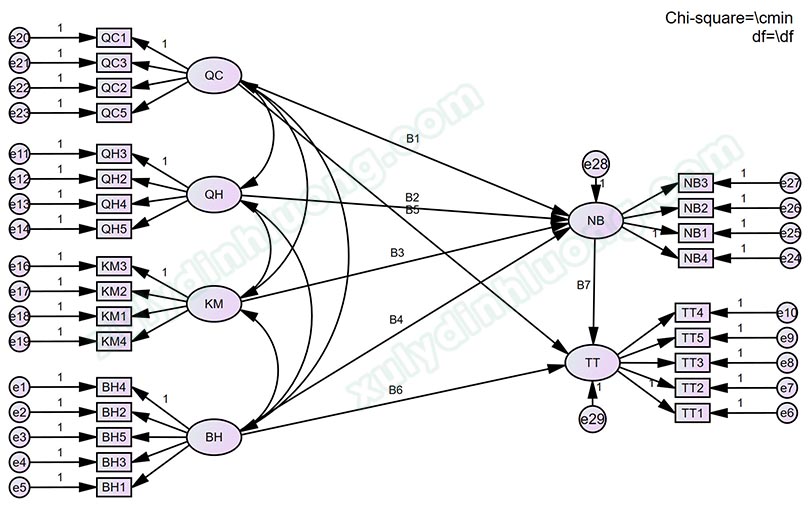
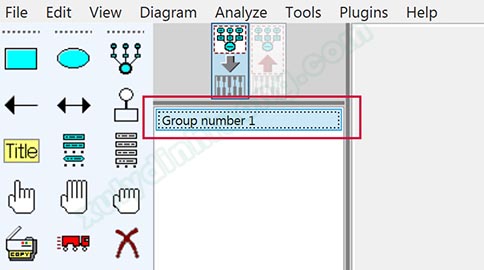
Bước 4: Khai báo các nhóm giá trị của biến Giới tính. Nhìn bên trái giao diện AMOS, chúng ta sẽ thấy dòng Group number 1, nhấp đôi vào dòng này.
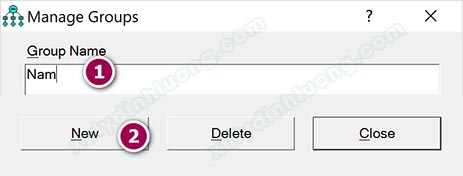
Bảng Manage Groups xuất hiện, tại đây chúng ta khai báo hai giá trị Nam/Nữ vào. Đổi tên Group number 1 thành “Nam”, sau đó tiếp tục nhấp New để tiền vào “Nữ”.
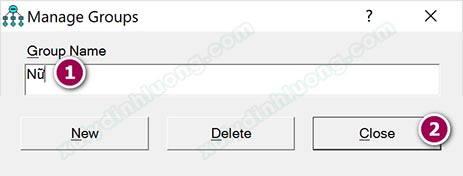
Tới đây chúng ta đã khai báo đủ 2 giá trị của biến Giới tính, do vậy sẽ nhấp vào Close để kết thúc quá trình khai báo. Nếu một biến định tính có 3 giá trị, chúng ta sẽ tiếp tục nhấp New và điền vào giá trị thứ ba và chọn Close. Cứ như vậy đến khi chúng ta hoàn thành nhập xong toàn bộ các giá trị của biến định tính.
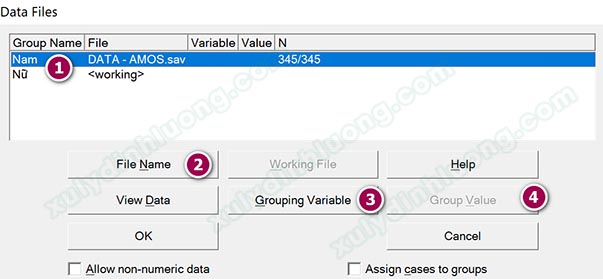
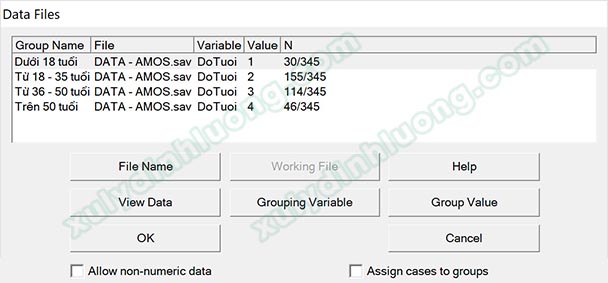
Bước 5: Nhập dữ liệu cho các giá trị biến Giới tính. Nhấp vào nút Select data file(s).
Cửa sổ Data Files hiện ra, tại đây chúng ta sẽ đưa dữ liệu vào các giá trị đã khai báo. Chúng ta thực hiện theo thứ tự đánh số 1, 2, 3, 4 cho từng nhóm giá trị biến Giới tính. Nhấp vào nhóm “Nam” > Nhấp vào File Name, tìm và mở file dữ liệu SPSS chạy SEM, cụ thể ở đây là file DATA-AMOS.sav.
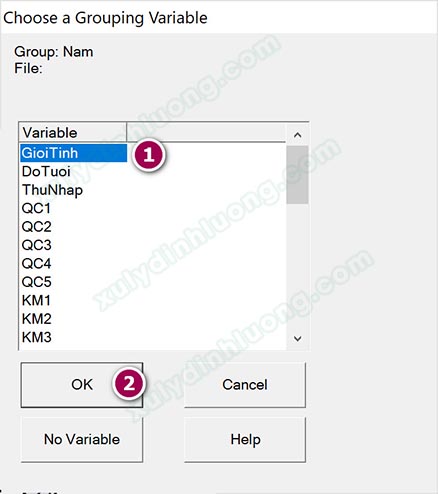
Nhấp vào Grouping Variable, một cửa số xuất hiện, tại đây tìm và chọn biến Giới tính, cụ thể ở đây là Gioi Tinh. Sau đó chọn OK.
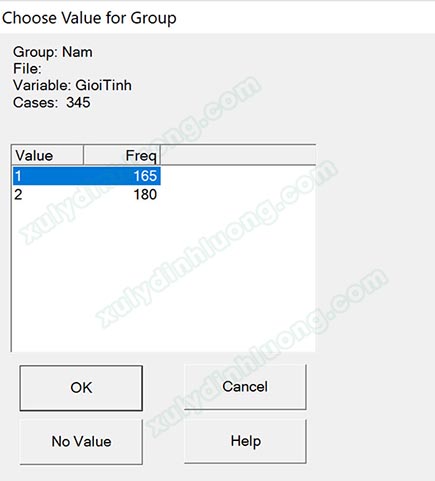
Lúc này mục số 4 – Group Value sẽ sáng lên, nhấp vào đó và chọn giá trị mã hóa tương ứng với tên nhóm. Biến Giới tính mã hóa 1 là Nam, 2 là Nữ. Chúng ta đang nhập dữ liệu cho nhóm Nam, do đó sẽ chọn giá trị 1 và nhấp vào OK để trở về cửa sổ Data Files. Tiếp tục nhấp OK để kết thúc.
Thực hiện tương tự cho nhóm “Nữ”, nhớ là mục số 4 – Group Value chúng ta sẽ chọn giá trị 2 tương ứng cho nhóm “Nữ”.
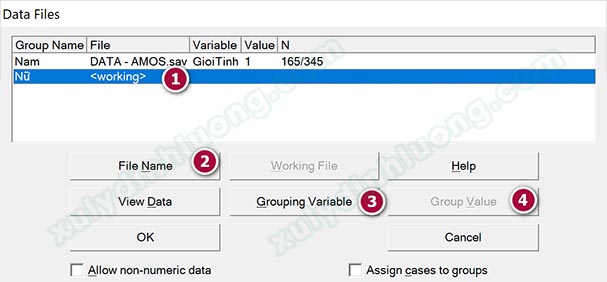
Kết quả hoàn chỉnh sau khi đã nhập dữ liệu cho các giá trị của biến Giới tính như sau. Thực hiện lưu lại file và kết thúc quá trình xây dựng diagram MHBB.
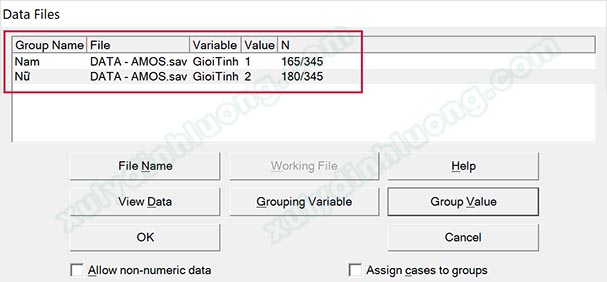
Bước 5: Tạo MHKB cho biến Giới tính bằng cách lưu mới (Save as) file GT-BB vừa thực hiện xong thành một file mới với tên GT-KB. Chúng ta thực hiện lại thao tác khai báo nhóm giá trị, nhập dữ liệu vào cho nhóm giá trị… giống như MHBB. Tuy nhiên, nhờ việc lưu mới kết quả từ file GT-BB nên các thông tin này đều được giữ từ MHBB rồi, chúng ta không cần phải làm lại nữa. Việc chúng ta cần làm là xóa toàn bộ các hệ số tác động B1, B2, B3… ở các đường dẫn đi để chuyển MHBB thành MHKB.
Kết thúc quá trình này, chúng ta đã tạo ra được 2 file MHBB và MHKB lần lượt là GT-BB.amw và GT-KB.amw. Lưu ý, trong khi phân tích CFA, SEM, tạo MHBB, MHKB,.. AMOS sẽ sinh ra các file tạm, các file này không cần dùng đến nên khi hoàn thành bài, các bạn có thể xóa nó đi, chỉ giữ lại các file định dạng .amw.
Bước 6: Lấy giá trị Chi-square và df ở hai mô hình bất biến và khả biến. Thực hiện phân tích SEM cho từng mô hình bằng cách nhấp vào nút Calculate estimates.
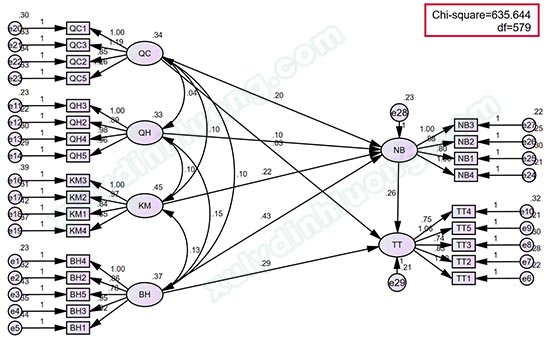
Kết quả MHBB như sau:
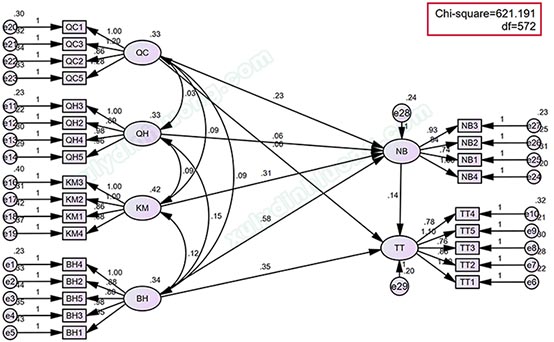
Kết quả MHKB như sau:
Bước 7: Tính toán giá trị p-value sai biệt Chi-square theo bậc tự do df. Các bạn tải file excel đã nhập công thức tính sẵn tại đây về máy.
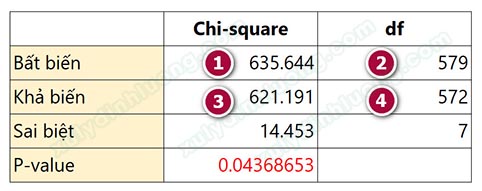
Nhập giá trị Chi-square và df tương ứng ở 2 hàng Bất biến và Khả biến, các chỉ số ở hàng Sai biệt và P-value sẽ tự động tính toán.
Giá trị p-value là 0.044 < 0.05 (độ tin cậy 95%), bác bỏ giả thiết H0, như vậy có sự khác biệt Chi-square giữa mô hình khả biến và mô hình bất biến. Nghiên cứu chọn mô hình khả biến để đọc kết quả vì có tính tương thích cao hơn. Kết luận: Có sự khác biệt mối tác động các biến trong mô hình giữa các đáp viên có giới tính khác nhau.
Khi có sự khác biệt mô hình giữa Nam/Nữ, chúng ta sẽ đánh giá sự khác biệt đó cụ thể thế nào thông qua 3 giá trị chính đã đề cập ở đầu bài viết là:
- Giá trị sig hoặc p-value (AMOS ký hiệu là p-value) dùng để xem mối tác động đó có ý nghĩa hay không lần lượt ở Nam/Nữ.
- Giá trị standardized regression weights (hệ số hồi quy chuẩn hóa) dùng để xem sự tác động ở Nam thấp hay cao hơn Nữ.
- Giá trị squared multiple correlation (R bình phương) dùng để xem mức độ giải thích của biến độc lập lên biến phụ thuộc trong một mối quan hệ tác động giữa Nam/Nữ cao thấp ra sao.
Chúng ta sẽ mở output của kết quả phân tích tại file GT-KB để đọc kết quả khác biệt. Phần đọc kết quả hoàn toàn tương tự như đọc kết quả phân tích SEM bình thường, chúng ta tập trung vào 3 bảng Regression Weights, Standardized Regression Weights, Squared Multiple Correlations. Sự khác biệt đó là lúc này 3 bảng kết quả này sẽ khác nhau khi chúng ta nhấp chọn Nam/Nữ ở phần bên dưới.
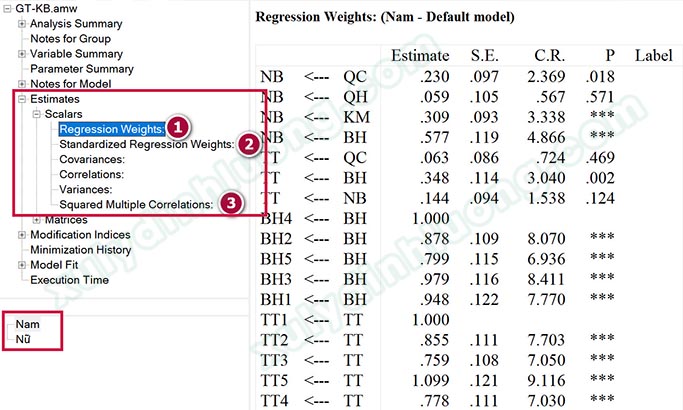
Đầu tiên, các bạn nên nhấp vào Nam, rồi đọc kết quả lần lượt ở 3 bảng 1, 2, 3. Sau đó, nhấp vào Nữ, đọc kết quả lần lượt ở 3 bảng. Để dễ so sánh sự khác biệt mô hình giữa Nam/Nữ, các bạn nên lập ra một bảng như mẫu bên dưới, các bạn có thể tải bảng này tại đây.
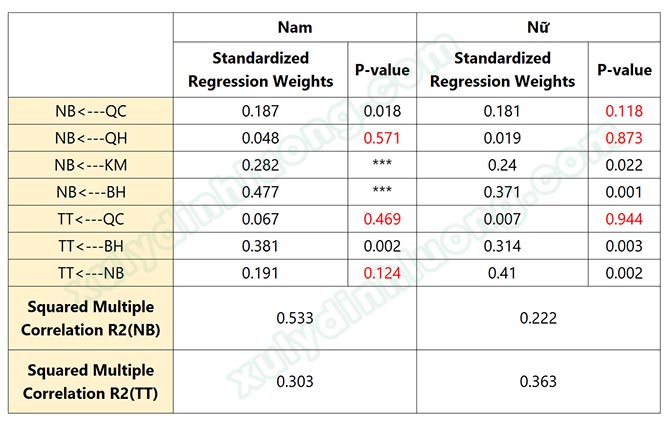
Diễn giải kết quả các bạn sẽ tự linh hoạt nhận xét, do sẽ có những mối tác động quan trọng/ít quan trọng cần nhấn mạnh giữa 2 nhóm đối tượng Nam/Nữ. Nhưng suy ra về cấu trúc nhận xét chung, các bạn sẽ xoay quay so sánh giữa Nam và Nữ thì mối quan hệ tác động nào có ý nghĩa, mối quan hệ nào không; với Nam thì biến A tác động lên C mạnh hơn so với B tác động lên C, trong khi đó với Nữ thì B tác động lên C mạnh hơn so với A; với Nam thì R2 của biến NB khá cao ở mức 0.544, trong khi đó với Nữ thì giá trị này chỉ là 0.222… Các bạn chỉ ra sự khác biệt về kết quả giữa hai nhóm Nam/Nữ.
3.2 Phân tích cấu trúc đa nhóm cho biến Độ tuổi
Thực hiện tương tự các bước với biến Độ tuổi. Biến định tính này có 4 nhóm giá trị, do vậy chúng ta cần tạo đủ 4 Group Name.
Kết quả đánh giá sai biệt Chi-square theo bậc tự do giữa hai mô hình khả biến và bất biến của biến Độ tuổi như sau.
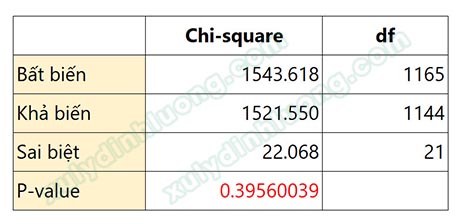
Giá trị p-value là 0.396 > 0.05 (độ tin cậy 95%), chấp nhận giả thiết H0, như vậy không có sự khác biệt Chi-square giữa mô hình khả biến và mô hình bất biến. Nghiên cứu chọn mô hình bất biến để đọc kết quả vì có bậc tự do cao hơn. Kết luận: Không có sự khác biệt mối tác động các biến trong mô hình giữa các đáp viên có độ tuổi khác nhau. Lúc này chúng ta sẽ đọc kết quả các chỉ số dựa theo file MHBB.
Thường với trường hợp không có sự khác biệt, chúng ta sẽ dừng ở phần kết luận không có khác biệt và không đi sâu vào đọc kết quả 3 giá trị chính ở file MHBB như cách đọc kết quả ở phần khác biệt. Bởi nếu không có khác biệt thì giữa các độ tuổi khác nhau mô hình đều như vậy, không có thông tin đặc biệt gì để chúng ta đi sâu vào phân tích.









